Image Text Extractor Project
The Image Text Extractor is a simple yet powerful web tool that allows users to upload an image containing text, and then extracts the text from that image using Optical Character Recognition (OCR) technology. This tool can be useful for digitizing printed or handwritten text from photos, making it easily accessible for editing, copying, or further processing.
Features
- Upload Image: Users can upload an image containing text (e.g., screenshots, printed pages).
- Text Extraction: The tool extracts the text from the uploaded image and displays it in a text box.
- Copy Functionality: A "Copy Text" button allows users to easily copy the extracted text to their clipboard.
How It Works
- User Uploads an Image: The user selects an image file using the upload form.
- Image Processing: The image is sent to the server, where it is processed by Python's Tesseract OCR library to extract the text.
- Display Result: The extracted text is sent back to the client and displayed in a text box, where the user can copy it if desired.
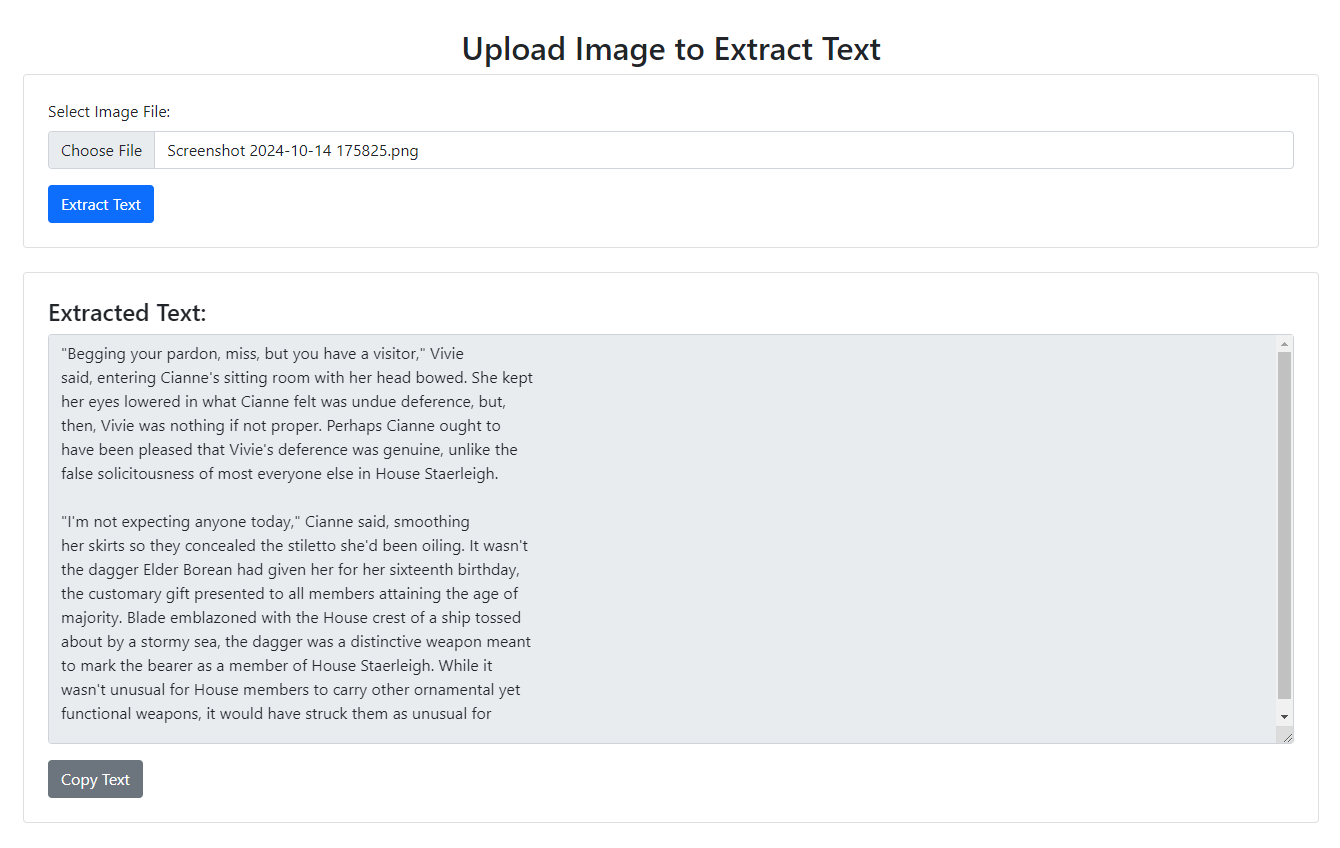
Project Example

Extracted Text Example:
Key Code Blocks
HTML Form for Image Upload
<form id="uploadForm" method="post" enctype="multipart/form-data" action="/upload">
<div class="mb-3">
<label for="imageInput" class="form-label">Select Image File:</label>
<input type="file" class="form-control" id="imageInput" name="image" accept="image/*" required>
</div>
<button type="submit" class="btn btn-primary">Extract Text</button>
</form>
This form allows the user to upload an image file. The image is then sent to the server for text extraction.
Python Flask Backend
@app.route('/upload', methods=['POST'])
def upload():
if 'image' not in request.files:
return jsonify({'error': 'No file part'}), 400
file = request.files['image']
if file.filename == '':
return jsonify({'error': 'No selected file'}), 400
try:
# Save the uploaded image to a temporary file
image_path = os.path.join('uploads', file.filename)
file.save(image_path)
# Perform OCR on the saved image
image = Image.open(image_path)
text = pytesseract.image_to_string(image)
# Clean up the temporary file
os.remove(image_path)
return jsonify({'text': text})
except Exception as e:
return jsonify({'error': str(e)}), 500
This code handles the image upload, saves it temporarily, processes it with Tesseract to extract text, and returns the result.